

Des ressources permettant d’évaluer la qualité des données de routine des établissements de santé relatives à la santé reproductive, maternelle, néonatale, infantile et adolescente (RMNCAH) sont désormais disponibles, sur la base des ressources élaborées pour un atelier organisé par Countdown the GFF à Nairobi, au Kenya, en juin 2022.
Les données provenant des établissements de santé individuels sont une source de données potentiellement riche pour informer les politiques et les programmes et suivre les progrès des pays vers les objectifs. L’adoption généralisée de la plateforme logicielle DHIS2 a rendu ces données plus accessibles que jamais. Cependant, les préoccupations et les questions relatives à la qualité des données ont souvent limité leur pleine utilisation. L’Organisation mondiale de la santé a développé des ressources liées à l’utilisation des données des établissements de santé, et Countdown a développé ce travail avec un ensemble de ressources pour évaluer la qualité des données.
Ce processus de qualité des données comprend :
- La compilation de toutes les données d’une manière standardisée.
- L’exécution de contrôles de qualité des données pour évaluer l’exhaustivité et la cohérence des rapports, et pour identifier les valeurs aberrantes et manquantes, en utilisant le code Stata.
- Corriger l’ensemble de données si nécessaire, en utilisant une piste d’audit claire pour documenter les modifications apportées aux données d’origine.
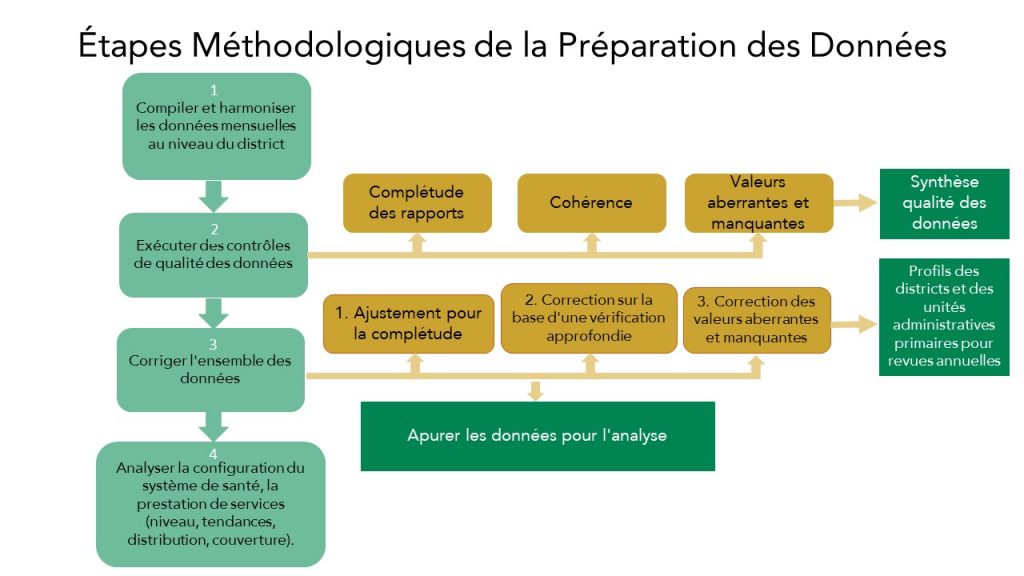
L’analyse comprenait des éléments de données relatifs à la grossesse, à l’accouchement, au planning familial, à la santé infantile, aux décès survenus dans les établissements et à la taille de la population, comme indiqué ci-dessous.

Compilation des données
Lors de la compilation des données, il convient de vérifier quelques points essentiels :
- Le nombre de districts est cohérent d’une feuille de calcul à l’autre.
- Les orthographes sont cohérentes entre les feuilles de calcul. Par exemple, si les orthographes comprennent « Nairobi », « Nairobi », « Nairoby », « NAIROBI », « nairobi », et « Nai-robi », Stata interprétera cela comme six valeurs différentes au lieu d’une.
- Les espaces supplémentaires invisibles sont inclus dans les variables de type chaîne.
- Les formats de date (mois et année) sont cohérents entre les feuilles de calcul.
- Les valeurs en double sont incluses.
- Des données manquantes existent, en termes de données non envoyées par les établissements de santé.
- Des zéros ont été insérés pour les valeurs manquantes, et vice versa.
Évaluer et ajuster les déclarations incomplètes
Le code Stata vérifie les taux de déclaration par type de service (planification familiale, soins prénatals, vaccination, consultations externes et séjours hospitaliers) et par année au niveau du district. Moins de 90% est considéré comme un faible taux de déclaration.
Il est important de tenir compte des déclarations incomplètes, car elles peuvent avoir un effet majeur sur les niveaux et les tendances de la couverture et d’autres statistiques dérivées des établissements de santé. Si nous ne tenons pas compte de l’exhaustivité, nous supposons qu’aucun service n’est fourni par les établissements qui ne font pas de déclaration, ce qui est généralement une hypothèse incorrecte.
Pour cette analyse, l’incomplétude peut se produire à deux niveaux :
1) Au niveau de l’établissement, parce que les établissements qui n’ont pas déclaré de données ; et
2) Au niveau des services, parce que les établissements n’ont pas déclaré de services ou de niveau de services attendus.
L’ajustement doit tenir compte des deux dimensions de l’incomplétude et doit faire une hypothèse sur le niveau des soins fournis dans les établissements de santé qui n’ont pas déclaré de données, par rapport à ceux qui l’ont fait. La formule d’ajustement pour déclaration incomplète est exprimée comme suit :
N(ajusté)=Nrapporté+Nrapporté* (1/(c)-1)*k
où N=nombre de services prestés, c=complétude des rapports, k=facteur d’ajustement.
- k=0 pas de services dans les établissements non déclarants
- k=0,25 certains services, mais beaucoup plus faible que les établissements ayant rapporté
- k=0,5 la moitié du taux par rapport aux établissements ayant rapporté
- k=0,75 presque autant que les établissements ayant rapporté
- k=1,0 même taux de services que les établissements ayant rapporté
Le choix du facteur d’ajustement (k) nécessite la consultation d’experts ayant une connaissance du système de santé du pays.
Valeurs aberrantes extrêmes et valeurs manquantes
De grandes variations dans le nombre de services fournis déclarés peuvent indiquer un problème de qualité des données, en particulier pour les interventions dont on sait qu’elles sont fournies à des niveaux de couverture élevés sur la base d’enquêtes de population. Cependant, les fluctuations du nombre de services déclarés peuvent se produire pour des raisons valables – telles que la croissance de la population, les changements d’activités programmatiques, ou les urgences telles que la pandémie de COVID-19. Ainsi, tout ajustement doit être effectué en consultation avec des experts qui connaissent le contexte local.
Pour les données annuelles, une valeur aberrante extrême est définie comme tout nombre dans l’ensemble de données supérieur ou inférieur à 5 écarts types de l’écart absolu médian (MAD) calculé sur les 3 années précédentes. La formule pour identifier les valeurs aberrantes est la suivante :
Médiane-1.4826*5*MAD < Xi > Médiane+1.4826*5*MAD ¥
Borne inférieure= Médiane – 1,4826 * 5 * MAD
Borne supérieure = Médiane + 1,4826 * 5 * MAD
où Xj est la valeur de l’observation pour une période donnée (année) et le MAD est défini comme l’écart absolu median
(MAD = médian(|Xje– X~|), où X~ est la médiane des trois années précédentes).
Les valeurs aberrantes extrêmes peuvent être corrigées en imputant une valeur basée sur la valeur médiane de l’année civile. Une imputation similaire peut être effectuée pour les valeurs manquantes.

Cohérence interne
La cohérence interne des services est vérifiée en comparant :
– Tle nombre de premières visites de soins prénatals (ANC1) déclarées et le nombre de premières doses de vaccin pentavalent (Penta1) et…
– le nombre de Penta1 et de troisième dose de vaccin pentavalent (Penta3).
Une méthode consiste à calculer un rapport entre ces deux nombres. Les ratios devraient se situer entre 1,0 et 1,5 ; d’autres valeurs nécessitent un examen plus approfondi des données.
Une deuxième méthode consiste à calculer la différence absolue entre le ratio attendu et le ratio déclaré des deux indicateurs. Le ratio attendu est calculé sur la base des données d’enquêtes sur les ménages, telles que les enquêtes démographiques et sanitaires {LINK ], si des données récentes avec un niveau de désagrégation approprié sont disponibles. Cette métrique est interprétée comme suit :
- <5 suggère une bonne qualité
- 5-14,9 suggère une qualité modérée
- ≥ 15+ suggère une qualité médiocre
L’utilisation d’un nuage de points pour comparer ANC1 à Penta1 et Penta1 à Penta3 est également utile pour comprendre les problèmes potentiels de qualité des données.

Tableau de bord de la qualité des données
Enfin, il est utile de résumer les évaluations de la qualité des données dans un tableau de bord, comme indiqué ci-dessous.

Présentation PowerPoint de l’atelier de Nairobi :
Fichiers do Stata:
D’autres ressources sont disponibles auprès de centre d’analyse et de données sur les établissements de santé.